Why GPT‑4 Codex Is the German Engineer You Need (And Claude Opus Is the Funny Coworker You Keep Around)
Key points
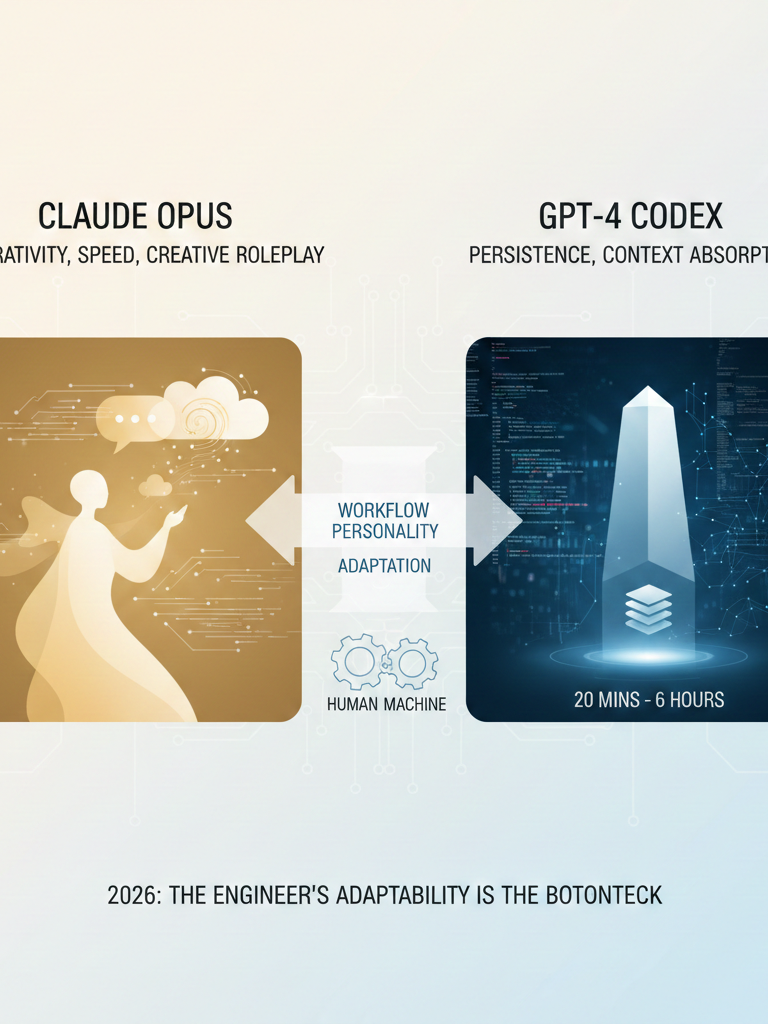
Opus excels at fast, interactive trial‑error; Codex specialises in long‑context, deep reasoning. Switching requires one‑week adaptation. Perceived intelligence drop is user adaptation, not model degradation. Pricing tiers ($20 vs $200) create false first impressions.
Key takeaway
The choice between Claude Opus and GPT‑4 Codex is not a test of raw intelligence—it is a choice between two radically different post‑training philosophies. Opus is optimised for interactivity, speed, and creative roleplay. It feels human, finishes your sentences, and is a joy to brainstorm with, but it requires constant steering to avoid shallow, localised solutions. Codex, by contrast, is optimised for persistence and context absorption. It disappears for 20 minutes to 6 hours, reads your entire repository, and returns with a monolithic solution that often works on the first try. The engineer who prefers one over the other is not making a factual claim about “better” code; they are revealing their own workflow personality. Switching between them demands a one‑week recalibration period, because you are not just learning a new API—you are learning a new culture of collaboration. The widely reported “model degradation” is almost never a real dumbing down; it is the user’s own growing familiarity and the increasing entropy of their codebase. In 2026, the most pragmatic conclusion is that both models are capable of state‑of‑the‑art results when driven by a skilled practitioner, and the real bottleneck is no longer the model—it is the engineer’s ability to adapt.
For anyone building software in 2026, the question is no longer whether you use an LLM—it is which one you marry.
The two reigning sovereigns are Claude Opus and GPT‑4 Codex. Both are terrifyingly capable. Both can generate production‑ready code. Yet they feel, behave, and collaborate like creatures from different planets. I have spent hundreds of hours with both, and I have come to believe that their differences are not about intelligence—they are about culture.
Let me start with Opus.
If you have never used it, imagine a co‑worker who bounds into the office, immediately understands the vibe of your project, and is desperate to please. It is the model that used to begin every response with “You’re absolutely right”—a phrase I am now allergic to, because it is the verbal equivalent of a golden retriever wagging its tail. Anthropic has mostly fixed this, but the spirit remains.
Opus is fast, interactive, and excels at roleplay. Give it a character prompt and it will inhabit that persona with unsettling fidelity. This makes it a phenomenal brainstorming partner. It generates ideas quickly, tries approaches immediately, and fails fast. You can have ten parallel sessions with Opus in an afternoon. It feels like the funny colleague you keep around even when he is a little silly.
Codex is the opposite.
It is the quiet person in the corner who never makes small talk but somehow remembers every line of code you ever wrote. When I described Opus as “a little too American,” the interviewer immediately said, “So Codex is German.” I will never be able to unthink that. It is perfect.
Codex does not flatter you. It does not say “great question!” It waits. You explain the problem. You provide context—lots of it, because by default Codex reads more of your repository than Opus ever will. Then it says “OK” and disappears for 20 minutes. Sometimes it takes 30, 40, 50 minutes. The longest I have waited was six hours. When it returns, it delivers a complete, coherent solution that often requires no further edits. This is not a bug; it is the feature.
OpenAI finally added a “deep mode” to formalise this behaviour. I mocked them for years about how interactive their model was; now they have seen the light.
The raw model weights are not that different.
The divergence happens in post‑training. Opus was aligned to be helpful, harmless, and—above all—conversational. It is optimised for low latency, which makes it feel intelligent in a chat interface but also encourages shallow, localised fixes. It runs off in one direction quickly. To get Opus to perform deep architectural reasoning, you must explicitly enter “plan mode” and fight its natural instinct to immediately write code.
Codex, by contrast, was post‑trained to persist. Its latency is higher by design; it spends that time attending to more tokens, reconsidering assumptions, and validating against the context you provided. It sometimes over‑thinks, but I prefer that. I would rather read one dense, correct output than engage in ten rounds of back‑and‑forth.
This philosophical gap creates a practical problem: switching costs.
I have watched developers pay $200 for the top Claude tier, then $20 for the OpenAI API, and immediately declare that Codex is “dumb” because the cheap tier is also the slow tier. They are used to Opus’s instant gratification; they try Codex, wait ten seconds, get impatient, and conclude it is inferior. This is a self‑inflicted wound.
OpenAI would be wise to offer even a small quota of the fast‑preview experience at the $20 level, because the current pricing psychology sets users up for failure. It takes a full week of deliberate use to develop a gut feeling for a model. It is like switching from a regular acoustic guitar to an electric—same chords, completely different touch. After seven days, you stop fighting the tool and start using its strengths.
The most entertaining consequence of this adaptation period is the “degradation myth.”
A new model launches. Reddit erupts with praise: “This is the smartest thing I have ever used.” Three weeks later, the same users complain: “They definitely dumbed it down. It used to be so much better.”
I am convinced this is almost never true. The model has not changed; the user has. They have grown accustomed to its brilliance, their project has accumulated technical debt, and they are asking the model to navigate a swamp of their own making. Why would any AI company intentionally quantize or lobotomise their flagship product? It would drive users directly to a competitor. At worst, they might serve a slightly quantized version during peak load—but that is a capacity trade‑off, not a conspiracy. The perceived decline is a cognitive illusion, amplified by the natural entropy of software projects.
So which is better?
It depends on what you value.
- If you enjoy the act of building, if you treat the model as a subordinate who needs direction, and if you want to iterate rapidly, Opus will delight you.
- If you care about efficiency, if you prefer to think deeply before writing code, and if you do not need your AI to be your friend, Codex is the more reliable partner.
Both can produce elegant solutions. Opus occasionally delivers surprisingly elegant code when you push it; Codex reliably delivers solid code without being asked. Neither is categorically superior.
One final observation:
OpenAI recently added a second personality mode to Codex—a “pleasant” variant that is supposed to be more conversational. I have not even tried it.
I like the bread. I like the dry, efficient weirdo in the corner. I do not need my AI to be my buddy; I need it to build things that work.
And in 2026, both of these models can do that, provided you are willing to spend a week learning how they think.
Frequently Asked Questions
Qany questions?
Please read the article carefully. If you have any questions, please contact [email protected].
Audio synthesized by Entity-Echo AI Agent