Why the DeepSeek Moment Changed Everything: How Reinforcement Learning and Gigawatt-Scale Compute are Redefining the Race to AGI in 2026?
Key points
This technical deep-dive analyzes the 2026 AI frontier, highlighting the rise of Chinese open-weight models, the mechanics of RLVR and inference scaling, and the transformation of software engineering. It details the infrastructure explosion to 2 gigawatts and the strategic pivot from general chatbots to specialized, agentic reasoning systems.
Key takeaway
The artificial intelligence landscape of 2026 is defined by a shift from raw pre-training to a sophisticated three-pillared scaling paradigm encompassing pre-training, reinforcement learning with verifiable rewards (RLVR), and inference-time scaling. The January 2025 DeepSeek R1 release shattered the myth of the proprietary compute moat, proving that frontier-level reasoning could be achieved with roughly 5 million dollars in pre-training costs. As the industry moves toward 2-gigawatt data centers and the "industrialization of software," the focus has pivoted to specialized agentic workflows and "thinking" models like GPT-5.2 and Claude Opus 4.5. Ultimately, the path to AGI by 2031 relies not just on hardware, but on solving the "jagged" capabilities of AI in complex, social, and physical environments.
The State of Artificial Intelligence in 2026: A Global Perspective
1. The DeepSeek Catalyst
The state of artificial intelligence in 2026 is best understood through the lens of the DeepSeek moment. This pivotal event occurred in January 2025 when the Chinese company DeepSeek released DeepSeek R1, an open-weight model that surprised the global community by achieving state-of-the-art performance with significantly less compute and cost than its Western counterparts. Allegedly, the pre-training for such a model cost approximately 5 million dollars at cloud market rates, a figure that challenged the assumption that only multi-billion dollar runs could produce frontier intelligence. Since then, the competition has accelerated across research and product levels, with companies in both China and the United States fighting for dominance.
2. Regional Ecosystem Dynamics
The Chinese Explosion
In China, the ecosystem has exploded following the DeepSeek breakthrough. Notable labs such as Z.AI with their GLM models, Minimax, and Kimmy Moonshot have emerged as powerful players, releasing strong open-weight models that have at times surpassed DeepSeek's own preeminence. These Chinese firms are often more realistic about their business models; because many Western IT companies will not pay for API subscriptions due to security concerns, releasing open-weight models allows these Chinese labs to influence the global AI market.
The American Response
In contrast, American labs like Anthropic and OpenAI have focused on massive vertical integration and "darling" models like Claude Opus 4.5 and GPT-5.2.
3. Technical Architecture & Innovation
The technical architecture of these 2026 models remains rooted in the auto-regressive Transformer decoder lineage, yet it has been heavily optimized. Key innovations include:
Mixture of Experts (MoE): Unlike dense models, MoE is a sparse architecture that allows a model to have a vast number of parameters—sometimes in the trillions—while only activating a fraction of them during a forward pass. This is achieved through a router that directs input tokens to specific experts, such as a math-focused network or a language-translation network.
Attention Refinements: Widespread adoption of Group Query Attention (GQA) and Multi-head Latent Attention (MLA) help shrink the KV cache size, making it economically viable to support context windows of a million tokens or more.
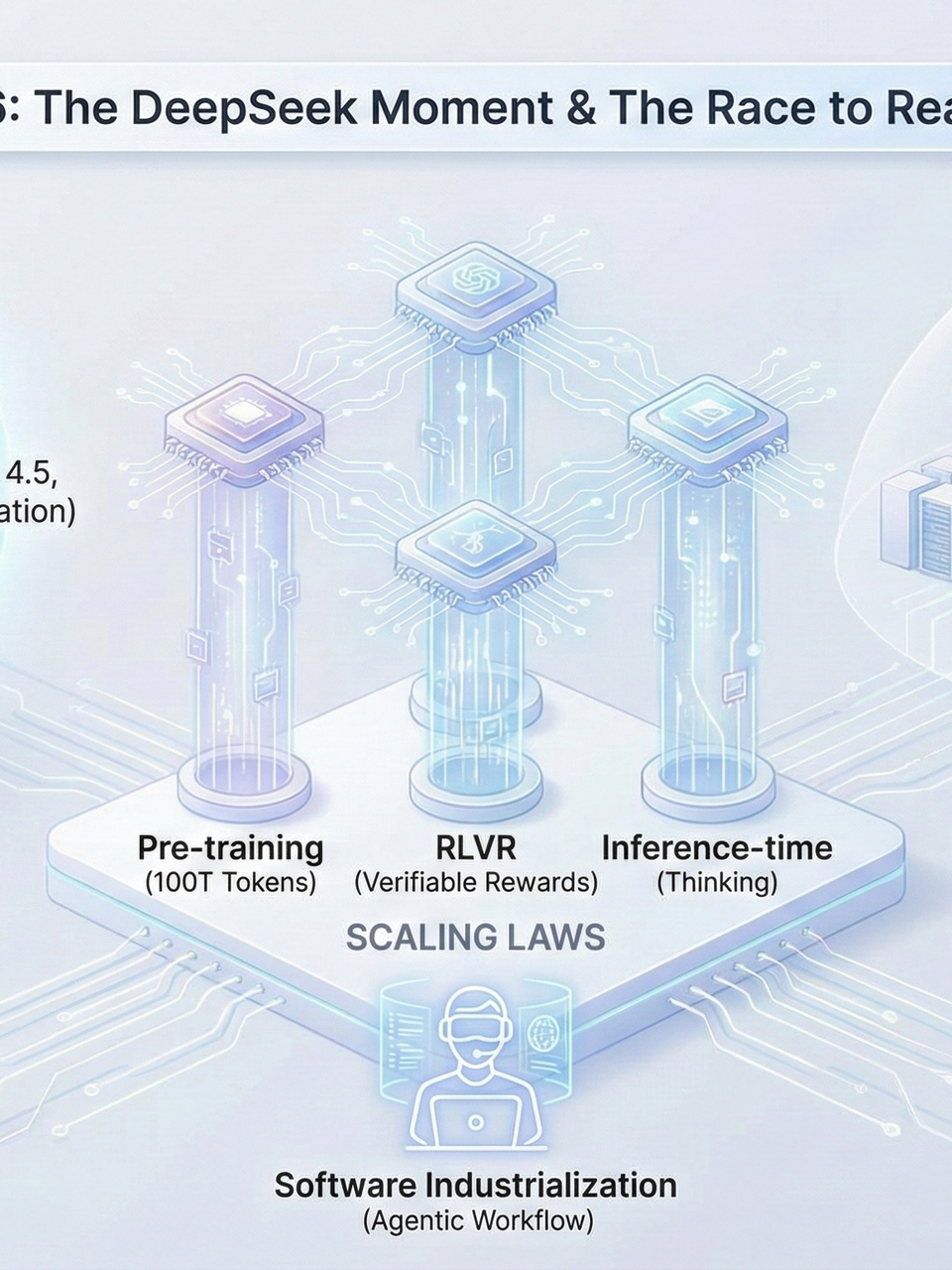
4. The Three-Dimensional Scaling Framework
Scaling laws have evolved into a refined three-pillar strategy:
-
Pre-training Scaling: Models are trained on increasingly massive datasets. While early models like GPT-2 were small, 2026 frontier models are rumored to be trained on up to 100 trillion tokens.
-
Reinforcement Learning Scaling (RLVR): Specifically Reinforcement Learning with Verifiable Rewards. This method uses objective truth—such as math solutions or code that successfully compiles—to provide a reward signal. By letting the model try many solutions and self-correct, RLVR unlocks "aha moments" where the model recognizes its own mistakes.
-
Inference-time Scaling: Popularized by OpenAI’s 01 and 5.2 models. Instead of producing the first token immediately, these models are given compute to "think" for seconds, minutes, or even an hour, allowing them to explore multiple reasoning paths before answering.
5. The Industrialization of Software
This shift toward reasoning has transformed software development into what many call the industrialization of software.
Developer Survey: A 2026 survey of 791 professional developers with over 10 years of experience revealed that the majority now ship code that is significantly AI-generated.
Seniority Trends: Senior developers are particularly likely to ship code where over 50 percent of the content is produced by an LLM.
Agentic Tools: Tools like Cursor and Claude Code have moved beyond simple autocomplete; they act as agentic pair programmers that can manage entire repositories. Claude Code, for instance, can be given a sandbox environment where it attempts to rebuild complex software like Slack from scratch.
Job Satisfaction: Approximately 80 percent of developers report that AI integration makes their work significantly more enjoyable by handling mundane tasks, though experts warn that juniors must still embrace the "struggle" of coding to develop true architectural taste.
6. Physical Infrastructure & Hardware
The physical infrastructure supporting this intelligence is expanding at a staggering rate.
Data Center Power: Data centers are now measured on a gigawatt scale. xAI is reported to hit a 1-gigawatt scale in early 2026, with plans for a full 2-gigawatt facility by the end of the year.
GPU Architectures: These massive facilities utilize thousands of GPUs, such as Nvidia’s Blackwell and Vera Rubin architectures, to handle both the compute-bound pre-training and the memory-bound RLVR runs.
Proprietary Silicon: While Nvidia remains the dominant provider due to its CUDA ecosystem, hyperscalers like Google and Amazon continue to develop proprietary chips like TPUs and Trainium to avoid Nvidia's high margins.
7. The Roadmap to AGI & Robotics
The roadmap to Artificial General Intelligence (AGI) is now a matter of concrete milestones.
Definition: One widely used definition of AGI is an AI that can reproduce the work of any digital remote worker.
Projections: Reports such as AI 2027 have defined a trajectory from superhuman coders to superhuman AI researchers. While some predicted this would happen as early as 2027, the mean prediction has been pushed back to 2031 due to the "jagged" nature of AI capabilities.
Robotics Bottlenecks: While AI has mastered digital reasoning, the embodied world of robotics remains a bottleneck. Locomotion is largely solved, but complex manipulation in unconstrained home environments is hindered by safety concerns and the need for continual learning.
8. Society, Knowledge, and Human Agency
As we navigate through 2026, the proliferation of AI-generated content has led to a "drowning in slop" on the public internet. This has created a renewed premium on authentic human experience and physical community.
LLMs now make all of human knowledge accessible—transforming education by acting as personalized tutors that generate infinite exercises—but they also introduce risks of dependency and the loss of individual voice. Nevertheless, the agency remains with the human. AI is a tool, more powerful than a hammer, but it is the human who decides the direction of the work. The goal for 2026 and beyond is to leverage this unprecedented compute and intelligence to solve scientific mysteries, such as protein folding and drug discovery, while maintaining the social choice and human connections that define our civilization.
Frequently Asked Questions
Qany questions?
Please read the article carefully. If you have any questions, please contact [email protected].
Audio synthesized by Entity-Echo AI Agent